What you’ll learn from this article:
- What regex is and how it works
- How regular expressions process and match text
- The core components that make up regex patterns
- How to use character sets, classes, and quantifiers
tl;dr:
Regex describes patterns in text. It’s great to quickly search, match, and manipulate specific strings, like finding all email addresses in a document or checking if a password meets certain rules.
Key findings
What is regex used for in everyday dev work?
It’s used in form validation, log filtering, web scraping, and data parsing — anything involving structured or unstructured text. Regex saves hours of manual coding.
Is regex hard to learn?
It looks intimidating, but once you understand the basics — like character sets and quantifiers — it’s surprisingly logical. Testing tools like regex101.com will make practice easier.
Craving more practical knowledge? Read on to learn the details of regex structure.
Regular expressions, often abbreviated as regex, are a powerful tool for searching, matching, and manipulating text. Despite their reputation for being complex and intimidating, they are a valuable skill for any developer to learn. Regex can make your life easier when filtering data, validating input, or performing complex search-and-replace operations.
This guide is designed for junior and regular developers who are new to regular expressions. By the end of this article, you'll have a solid understanding of regex syntax and how to start using it in your preferred programming language.
What is regex?
Regex, short for "regular expression," is used in text processing for defining patterns that can match specific sequences of characters within a target string. Imagine a tool that allows you to search through text and instantly find or replace sections that fit a particular pattern. This is exactly what regex does. It helps you automate and simplify the task of identifying and manipulating text data in various ways.
The essence of regex lies in its ability to describe a sequence of characters. This description, known as a regular expression pattern, acts as a blueprint for what you are looking for in the text.
For example, suppose you need to find all email addresses in a document. In that case, you can build a regex pattern that recognizes the general structure of an email address, such as characters before and after an @ symbol and a domain name with a dot. This regular expression pattern can then scan through the text, identify each matching string that fits the email address format, and either extract, validate, or replace them.

Regex patterns are highly flexible and can be used for a variety of tasks beyond simple searches. You can use them to replace specific patterns of text with new content, validate input formats like dates or phone numbers, and even perform complex data transformations.
How regex works
To understand how regular expressions work, consider the following example:
The pattern a.b.
This simple pattern will match any string of three characters where the first character is a, the last character is b, and there is exactly one character, any character, in between. So, it would match strings like aab, acb, or a0b The dot . in this pattern is a wildcard character representing any single character. This feature makes regular expressions extremely useful because you can create specific and flexible patterns, depending on your needs.
Key components of regex
Regular expressions are composed of various elements that work together to define patterns. Here’s a breakdown of the key components that can make up a regex pattern:
Literals and metacharacters
Literals are the simplest part of regular expressions. They match exactly what they represent. For example, if you want to find the word cat in a text, you use the pattern cat, which will match the exact sequence cat in any input string.
Metacharacters are symbols that have a special meaning in regular expressions. They do not match themselves but rather dictate how the regex engine should interpret the characters around them.
.– Matches any single character except a newline character.*– Matches zero or more characters of the preceding element.+– Matches one or more characters of the preceding element.?– Matches zero or one occurrence of the preceding element.^– Anchors the match at the start of a string.$– Anchors the match at the end of the string.
Character classes and sets
Character classes are used to match any one of a set of characters. They are enclosed in square brackets []:
[abc]– Matches any single charactera,borc.[^abc]– A character class can be negated with a ^ at the beginning, like[^abc], which matches any character excepta,b, orc.
A character range allows you to specify a sequence of characters, such as [a-z] for any alphabetic characters (both lowercase letters and uppercase letters) or [0-9] for digits. This makes your regular expression more concise and easier to read.
[a-z]– The character class[a-z]matches any lowercase letter fromatoz. This means that the regex pattern will match any letter between a and z in the input string.
Special character classes
These special character classes are shorthand for commonly used character sets.
\d– Matches any digit, equivalent to [0-9].\D– Matches any non-digit character.\w– Matches any word character (alphanumeric + underscore), equivalent to [a-zA-Z0-9_].\W– Matches any non-word character.\s– Matches any space character (space, tab, newline).\S– Matches any non-whitespace character.

Quantifiers
Quantifiers define how many times an element must occur for a match. These are useful for defining patterns that match varying character lengths and numbers.
_*– Matches zero or more occurrences of the previous element. For example, the pattern a matchesaaa,aaa, or even an empty string.+– Matches one or more occurrences of the previous element. For instance, the pattern\d+will match one or more digits in the string, so it matches123in the stringabc123def.?– Matches zero or one time of the previous element. The patterncolou?rmatches bothcolorandcolourbecause theu?indicates thatuis optional.{n}– Matches exactly n occurrences of the previous element. For example,a{3}matches exactlyaaa.{n,}– Matches at leastntimes. The patterna{2,}matchesaa,aaa, or any longer sequence ofa"s.{n,m}– Matches betweennandmtimes. For example,a{2,4}matchesaa,aaa, oraaaa.
Greedy vs non-greedy
Normally, quantifiers like \* (zero or more) and + (one or more) are greedy, meaning they try to match as many characters as possible. Adding ? after these quantifiers makes them non-greedy, meaning they will match as few times as possible.
For example, the pattern a.*b is greedy and will match from the first a to the last b in the string aabab, matching aabab. In contrast, the pattern a.\*?b is non-greedy and will match the shortest possible string, which is aab.
Anchors and boundaries
Anchors specify positions within the text, ensuring matches occur at specific points.
^– Matches the start of the string.$– Matches the end of the string.\b– Matches a word boundary.\B– Matches a non-word boundary.
Groups
Groups in regex allow you to treat a part of the pattern as a single unit. This means you can apply quantifiers to the entire group, capture the matched substring for later use, or use it in backreferences to match the same content again elsewhere in the pattern. Groups are defined using parentheses ().
(abc)– Capturing group for matching and extracting substrings.(?:abc)– Non-capturing group, useful for applying quantifiers without capturing.
Capturing groups
A capturing group is created by placing a part of the regex pattern inside parentheses (). When the regex engine finds a match for the group, it captures the matched text and stores it for future reference. The captured text can be used in subsequent operations, such as replacing matched text with different content or rearranging the order of text.
For example, the regular expression (\d{4})-(\d{2})-(\d{2}) used on the string 2023-06-15 captures 2023, 06, and 15 as distinct groups, allowing you to access and manipulate these parts individually.
Alternation
Alternation in regex allows you to specify a choice between multiple patterns. It is like an OR operator and is represented by the pipe symbol |. This enables the regular expressions to match one of several patterns at a particular position in the text.
|– Alternation, equivalent to a logical OR. For example,a|bmatchesaorb.
Character escapes
If you need to match characters literally, you must use an escape sequence. The escape character is a standard backslash (\). Backslash escapes allow you to match for any of the metacharacters, such as ? and $.
For example, \. matches a literal character decimal point or dot.
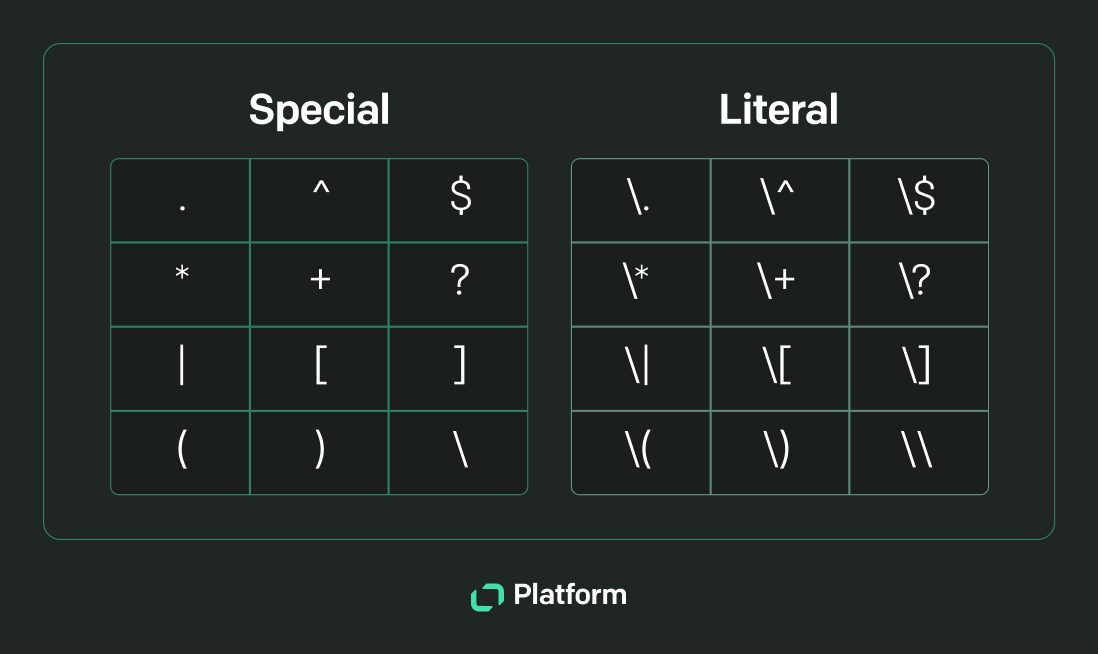
More explanations and examples of regex components
Matching word characters
In regex, a word character is any alphanumeric character, including underscores. It is often represented by the shorthand \w, which matches any single character that is a letter, digit, or underscore.
This is useful when you need to match parts of words, such as extracting or validating individual components like usernames, file names, or identifiers.
Anchoring to the end of the string
Without the $ anchor, a regular expression pattern could match a substring anywhere within the text, which might lead to unintended or incorrect matches. By anchoring the pattern to the end, you prevent these partial matches and guarantee that only strings ending with the desired pattern are matched.
For example, if you want to match the word end only if it appears at the very end of the string, you would use the pattern end$:
Handling whitespace characters
Whitespace characters are invisible characters in text that help to separate words and lines. They include spaces, tabs, and line breaks and play a key role in text formatting and layout.

These characters are represented by \s. This is useful for matching patterns that include or are surrounded by whitespace. You can also use find and replace excessive whitespace or to format text consistently:
Matching an entire string
To match an entire string, you need to design your pattern in such a way that it spans from the very beginning to the very end of the string. You can use the special anchors ^ at the start and $ at the end of your regular expression pattern.
Matching word boundaries
Word boundaries in regex are special positions that signify the start or end of a word. They help ensure that a pattern matches only complete, standalone words rather than substrings within longer words. Word boundaries are particularly useful for tasks where you need to find precise word matches within text and avoid accidental matches within longer words.
The symbol \b represents a word boundary. It is not a character itself but rather a position between characters. Using the pattern \bcat\b would not match catfish but it would match cat in cat is cute:
Dealing with empty strings
An empty string is a string with no characters.It is important to know how to handle them in regex. Sometimes, you might need to explicitly match an empty string to indicate the absence of characters where something could have appeared. This can be useful in scenarios like validating fields in a form where some fields might be optional.
To match an empty string explicitly, you can use the pattern ^$. This pattern asserts that there is nothing between the start (^) and end ($) of the string, meaning the string is empty.
Regex in different programming languages
While regex syntax is fairly consistent across different programming languages, there can be subtle variations in how patterns are used or how functions are called. It’s essential to grasp these nuances to write effective regex patterns in whichever language you’re working with.
JavaScript
In JavaScript, regex can be created in two ways: using the RegExp constructor or by enclosing the pattern in slashes. The latter is more common and concise. JavaScript's regular expression implementation is versatile and supports a wide range of regex features, making it useful for web development tasks like form validation, data extraction, and string manipulation.
Using the RegExp constructor
Regular expression objects in JavaScript can be created dynamically using the RegExp constructor. This method is particularly handy when the pattern needs to be generated at runtime, offering flexibility for more complex applications.
Using literal notation
For most scenarios, creating a regular expression object with literal notation is more straightforward. This method involves enclosing the pattern directly in slashes, ideal for static patterns that do not need to change.
Here, regex is a regex object created using literal notation. This method is quick and effective for defining and using patterns that are known ahead of time.
Python
In Python, regex functionality is provided by the re module, which offers a suite of tools for searching, matching, and manipulating strings. Python's regex features are robust, making it an excellent language for tasks such as data cleaning, text analysis, and natural language processing.
Python also supports raw strings, which are prefixed with r and treat backslashes as literal characters. These are especially useful when writing regular expressions because they prevent the need for escaping backslashes.
For example, writing a pattern like \\d+ would normally require double backslashes in a regular Python string to escape them. However, using a raw string, you can simplify this to r'\d+', making your patterns clearer and less error-prone.
PHP
PHP uses the preg family of functions for regex operations, including preg_match, preg_replace, and preg_split. These functions are powerful tools for server-side text processing tasks such as form validation, data extraction, and content formatting.
C#
In C#, regular expression functionality is provided by the System.Text.RegularExpressions namespace. This namespace includes classes like Regex, which can be used to perform complex pattern matching and text manipulation operations commonly needed in applications such as log analysis, data validation, and text parsing.
The four most useful regex patterns
Below are four practical and very common patterns that you can apply in various projects for text validation:
Email validation
This regex expression is used to validate email addresses, following the standard format of username@domain.extension:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
Phone number validation
This expression matches phone numbers in various formats, including optional country codes and separators:
^\+?(\d{1,3})?[-.\s]?(\d{1,4})[-.\s]?(\d{1,4})[-.\s]?(\d{1,9})$
URL validation
This pattern is used to validate URLs, following the standard URL format:
^(https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([/\w .-]*)*\/?$
The (https?:\/\/)? matches an optional http or https followed by ://. While the s? allows for both http and https.
IP address validation
This expression validates IPv4 addresses, checking that they are in the format of four octets (for example, 192.168.1.1):
^(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$
Advanced regex techniques
Regex can be taken to a higher level of sophistication with advanced techniques that allow for more precise and complex regex patterns. Understanding these techniques can greatly enhance your ability to manipulate and extract data from text in real-life applications.
Lookahead and lookbehind
Lookahead and lookbehind assertions are zero-width assertions that allow you to match a pattern only if it is followed or preceded by another pattern, without including the secondary pattern in the match. This is useful for checking for conditions that must be true for a match to occur, without actually matching the condition itself. There are two types of lookahead and lookbehind: positive and negative.
(?=abc)– Positive lookahead. Matches a position followed by "abc."(?!abc)– Negative lookahead. Matches a position not followed by "abc."(?<=abc)– Positive lookbehind. Matches a position preceded by "abc."(?<!abc)– Negative lookbehind. Matches a position not preceded by "abc."
Named groups
Named groups allow you to assign names to capturing groups within a regex pattern. This feature improves readability and makes it easier to reference and manipulate captured data, especially when working with complex patterns or when the regex captures multiple groups.
(?<name>[a-zA-Z]+)
Unicode support
Unicode support in regular expressions allows you to match text in various languages and symbols, significantly extending beyond the limitations of the ASCII character set. ASCII characters represent only a small subset of all possible characters, mainly focusing on English letters and symbols, while Unicode covers a wide range of characters from different languages and scripts worldwide.
This makes your regex patterns more versatile and internationally applicable. To match Unicode characters, use \u followed by the character's hexadecimal code:
- \u00E9 # Matches
é
Steps for creating a regex pattern
Creating a regex pattern can seem daunting at first, but by breaking it down into manageable steps, you can tackle it systematically. We’ll walk you through the process of creating a regex pattern to match dates in the YYYY-MM-DD format.
By breaking down this example, we’ll illustrate each step required to build an effective regex pattern, which you can then apply to other scenarios.
1. Identify what you need to match
Clearly define what text you want to find or manipulate. For instance, are you looking for email addresses, phone numbers, or dates?
- In our case, we want to match for dates in the YYYY-MM-DD format.
2. Break down the target text
Identify the components of the text you need to match, such as numbers, letters, specific symbols, or a combination of these.
For example, with dates in the format YYYY-MM-DD:
- YYYY is a 4-digit number.
- MM and DD are 2-digit numbers.
3. Choose appropriate regex elements
Decide which regex components (literals, character classes, quantifiers, etc.) match each part of the text. For example, we would use:
\d{4}for YYYY (four digits).\d{2}for MM and DD (two digits each).- Hyphens as literals.
4. Construct the basic pattern
Start building your regex by combining the elements you’ve identified. Combining the components for the date would give us:
\d{4}-\d{2}-\d{2}
5. Test your pattern
Use a regex testing tool to check your pattern against sample text. Adjust as needed for accuracy and completeness.
6. Handle edge cases
Think about possible variations of the text you’re matching and refine your pattern to handle these cases. Check that your date pattern handles invalid months or days. You might need a more complex regex pattern to validate dates accurately.
7. Optimize for readability and performance
Make sure your regex is as simple as possible while being comprehensive enough to cover all cases. Remove unnecessary elements that don’t add to the matching criteria.
- Since we're only matching YYYY-MM-DD, we don’t need to account for other date formats, which means our complete regular expression pattern is
\d{4}-\d{2}-\d{2}.
Regex practice exercises with step-by-step explanations
To help you become more comfortable with regex, we'll now walk through a few more practical exercises. These exercises will illustrate how to create regex patterns and understand their components.
Exercise 1: Matching email addresses
Objective: Create a pattern to validate and extract email addresses from a sample input string.
Input String: Please contact us at support@example.com or admin@domain.org. You can also reach out to info@example.net.
Steps:
- Identify the components:
- An email consists of a username, an @ symbol, a domain name, and a top-level domain (TLD).
- The username may include letters, digits, dots, underscores, and hyphens.
- The domain name typically includes letters, digits, and hyphens.
- The TLD is usually 2-6 letters.
- Break down the pattern:
- The username can be represented as
[a-zA-Z0-9._%+-]+to allow one or more of the specified characters. - The domain name is
[a-zA-Z0-9.-]+. - The TLD is
[a-zA-Z]{2,6}.
- The username can be represented as
- Construct the pattern:
- Combine the components to form the full pattern:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,6}$.
- Combine the components to form the full pattern:
Solution:
import re
text = "Please contact us at support@example.com or admin@domain.org. You can also reach out to info@example.net."
pattern = r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,6}"
emails = re.findall(pattern, text)
print(emails) # Output: ['support@example.com', 'admin@domain.org', 'info@example.net']
Exercise 2: Validating phone numbers
Objective: Create a pattern to match phone numbers in different formats, including optional country codes.
Input String: You can reach us at +1-800-555-5555, 800.555.1234, or 123-456-7890.
Steps:
- Identify the components:
- Phone numbers may start with an optional country code prefixed by
+. - They can be separated by hyphens, dots, or spaces.
- The main number consists of a sequence of digits, usually grouped in 3-4 digits.
- Phone numbers may start with an optional country code prefixed by
- Break down the pattern:
- The country code can be represented by
\+?\d{1,3}. - The separators can be
[-.\s]?. - The main number groups are represented by
\d{1,4}.
- The country code can be represented by
- Construct the pattern:
- Combine the components into a full pattern:
^\+?(\d{1,3})?[-.\s]?(\d{1,4})[-.\s]?(\d{1,4})[-.\s]?(\d{1,9})$.
- Combine the components into a full pattern:
Solution:
import re
text = "You can reach us at +1-800-555-5555, 800.555.1234, or 123-456-7890."
pattern = r"\+?(\d{1,3})?[-.\s]?(\d{1,4})[-.\s]?(\d{1,4})[-.\s]?(\d{1,9})"
phone_numbers = re.findall(pattern, text)
formatted_numbers = [''.join(number) for number in phone_numbers]
print(formatted_numbers) # Output: ['+18005555555', '8005551234', '1234567890']
Exercise 3: Extracting URLs
Objective: Create a pattern to extract URLs from a sample input string.
Input String: Visit our website at http://example.com or https://example.org for more information. Also, check out www.example.net.
Steps:
- Identify the components:
- URLs may start with
http://orhttps://. - They have a domain name and an optional path.
- URLs may start with
- Break down the pattern:
- The protocol part can be
https?://(optional). - The domain name can be
[\da-z.-]+. - The TLD can be
[a-z.]{2,6}. - The path can be
([/\w .-]*)*.
- The protocol part can be
- Construct the pattern:
- Combine the components to form the full pattern:
^(https?:\/\/)?([\da-z.-]+)\.([a-z.]{2,6})([/\w .-]*)*\/?$.
- Combine the components to form the full pattern:
Solution:
import re
text = "Visit our website at http://example.com or https://example.org for more information. Also check out www.example.net."
pattern = r"https?://[a-zA-Z0-9.-]+\.[a-zA-Z]{2,6}(/[a-zA-Z0-9._/-]*)?"
urls = re.findall(pattern, text)
print(urls) # Output: ['http://example.com', 'https://example.org']
Tips for mastering regex
Regular expressions are a great tool to add to your programming toolkit, but mastering them requires practice, exploration, and a deep understanding of their capabilities. Here are some tips to help you become proficient with regex:
1. Practice regularly
Regular practice helps you internalize regular expression concepts and build intuition for creating effective patterns.
Just like learning a new language or instrument, the more you practice with regex, the more familiar you will become with its syntax and nuances. Experimenting with different patterns on a variety of text inputs allows you to understand how regex operates under different scenarios.
Set aside time each day to solve regex challenges. Websites like Regex Crossword offer a variety of problems that can help you practice.

2. Use online tools
Online regex tools can simplify the process of creating, testing, and visualizing regex patterns, making them more accessible and easier to understand.
Tools like Regex Builder provide interactive platforms to test regex patterns against sample text, see real-time matches, and get detailed explanations of each component in your pattern.
3. Start simple
Beginning with simple regex patterns helps you build a solid foundation and prevents frustration from trying to tackle overly complex tasks too soon.
Start by creating simple patterns that match basic text, such as single characters or fixed sequences ( abc, [a-z], \d, etc.). Once you are comfortable with simple patterns, introduce more complexity by combining different elements, such as using quantifiers with character classes ([a-z]{2,5}) or adding anchors (^abc$).
4. Read documentation
While the core principles of regular expressions are consistent across languages, there are often subtle differences in syntax, supported features, and performance considerations. Reading the documentation helps you avoid common pitfalls and take full advantage of the regex features available in your language of choice.
Regularly refer to the official documentation for the programming language you are using. For instance, Python has the re module documentation, JavaScript provides information on RegExp objects, and Java details regex usage in its Pattern class documentation.
Make text work for you
With regex at your fingertips, you’ll have the power to handle text like never before, transforming how you approach and solve problems in your projects. Whether you're cleaning data, parsing logs, or crafting complex search patterns, regular expressions will simplify your work and open up new possibilities. Happy regexing!


